Agentic development: from fear to evidence
Over the last year I’ve watched two different approaches to AI adoption play out inside a regulated financial institution.
One approach started with governance. Policies, controls, approval processes, risk reviews, and discussions about what might go wrong.
The other started with a small engineering team trying to build something real. They assembled a software factory in a controlled environment, experimented with agent workflows against actual engineering tasks, and gradually expanded what the system could do. The team is now preparing to trial the approach with a production engineering pod.
The concerns in regulated environments are legitimate. The cost of being wrong can be significant. Financial loss, customer impact, compliance issues, operational risk, and erosion of trust all matter. The challenge is that governance discussions often happen without a concrete system to govern. It’s difficult to reason about controls, boundaries, ownership, and accountability in the abstract.
Building a small, observable system changes the conversation. The discussion shifts from hypothetical risks to specific risks. From generic controls to targeted controls. From assumptions to evidence.
That experience changed how I think about autonomy
I used to think of governance and automation as opposing forces. One slows things down, the other speeds things up. Increasingly, I think they’re the same thing viewed from different angles. The systems that can safely automate the most work are usually the systems with the clearest definitions, ownership boundaries, constraints, and verification mechanisms.
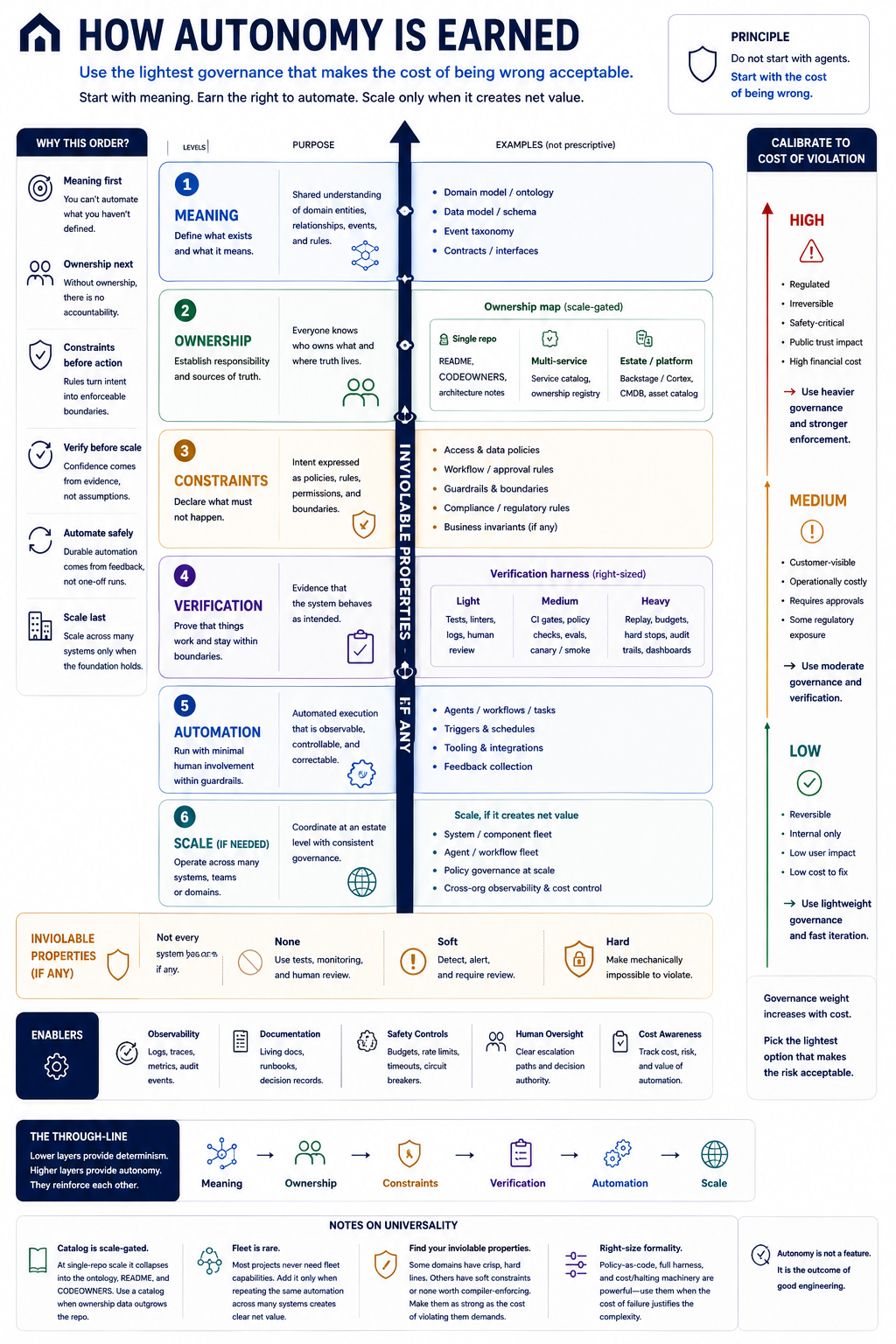
The diagram is my attempt to capture that idea.
At the bottom is meaning. Before a system can make decisions, the things inside that system need shared definitions. Whether you call it a domain model, ontology, or contract matters less than the outcome: everyone agrees what exists and how it relates to everything else.
Next comes ownership. Someone needs to know who owns what, where the source of truth lives, and who is accountable when something changes. At small scale this might be a repository, architecture notes, and CODEOWNERS. At larger scale it becomes a catalog. The implementation changes, but the principle doesn’t.
Then come constraints and verification. Rules define what must not happen. Verification provides evidence that the system behaves as intended. The right level of formality depends on the cost of failure. Some systems need little more than tests and human review. Others justify policy-as-code, replay systems, audit trails, and hard enforcement boundaries.
Only then do we arrive at automation.
Agents are not the foundation. They are consumers of the layers beneath them. An agent operating inside a well-defined environment with clear constraints and verification is fundamentally different from an agent operating on hope and a prompt.
Scale comes last, if it comes at all. Most projects will never need fleets of agents or highly automated estates. That’s fine. Scale is not the goal. Safe, useful automation is the goal.
The most useful question I’ve found is not how autonomous a system can become. It’s what level of governance makes the cost of being wrong acceptable.
That framing changes the conversation. It moves the discussion away from tools and toward engineering. Away from abstract fears and toward observable systems. Away from autonomy as a feature and toward autonomy as an outcome.
Good systems don’t become autonomous because someone added agents.
They become autonomous because the layers underneath them make autonomous operation safe.